
Dans cet article sans prétention, nous allons revenir dans les grandes lignes sur ChatGPT et tout ce qui l’entoure, et essayer de le mettre en perspective avec une vision éthique et responsable de l’IA en particulier mais, surtout, de l’informatique en général.
TL&DR : Moui, mais avec beaucoup de modération.
NDLR : Certains liens sont tout public, d'autres sont pour les plus tech’ savy.
Le fonctionnement de l’intelligence artificielle ChatGPT en quelques mots
Vous le connaissez sans doute déjà : tout le monde en parle. Il peut parler, il est vraiment bluffant. Il donne l’impression qu’on peut tout lui demander : des recettes de cuisine, du code, des idées pour changer le monde… et il y arrive la plupart du temps !
Et contrairement à Google, Bing ou Qwant, il le fait en langage naturel et non sous forme de liens hypertextes : même plus besoin de cliquer !
Mais, finalement, ChatGPT c’est un produit. Et pour construire ce produit d’IA, quelques ingrédients sont nécessaires, et ils ne sont pas forcément à la portée de tout le monde.
ChatGPT, un (énorme) consommateur de data
Déjà, il faut des données. Beaucoup de données. Vraiment, beaucoup… beaucoup de données. On parle de corpus de textes (Common Crawl, Wikipedia, des livres, etc.) qui mis bout à bout représentent environ 500 000 000 000 de mots. Sachant que sur Wikipedia (tous langages confondus), il y a environ 600 000 000 mots, ça fait pas mal de lecture.
Toutes ces données sont ensuite ingurgitées par un modèle gigantesque composé de centaines de milliards de paramètres.
ELI5
Les paramètres ce sont toutes les variables (des nombres) qui vont être modifiées tout au long de l'entraînement du modèle. [Voir ici pour une introduction sur l’entraînement des réseaux de neurones].
Ces paramètres encodent tout un tas de relations sémantiques. Par exemple, que le mot le plus probable après “lundi, mardi, mercredi, [?]” est jeudi. Ou que, généralement, lorsqu’un mot est précédé par “les”, on va ajouter un “s”.
Soyons clairs, personne n’a littéralement appris à ChatGPT les règles de grammaire régissant le français, l’anglais ou le mandarin. Mais, à force de répétitions, à force de “voir” les mêmes “tokens” (mots) se suivre, le modèle apprend à reconnaître les mots les plus probables en fonction d’un contexte donné.
Ce modèle gigantesque, c’est GPT. Le LLM (Large Language Model ou giga-modèle pour les amoureux de la langue française) caché derrière ChatGPT. Mais il manque un ingrédient essentiel à GPT pour lui permettre d’interagir naturellement avec ses utilisateurs : l’humain.
Une touche humaine dans GPT avec l’approche RLHF
Dans leur version vanilla, les LLM comme GPT apprennent à compléter des textes avec le token (mot) le plus probable. C’est-à-dire le token qui est rencontré le plus souvent dans ce type de contexte, sur internet [pour faire court]. Mais ce qui intéresse les utilisateurs, c’est de recevoir une réponse à leur question, pas d’avoir un modèle qui essaye de compléter leur entrée. Cette problématique est connue sous le nom de Model Alignement, ou comment faire converger les capacités sémantiques d’un LLM avec l’intention de l’utilisateur.
Pour ChatGPT, OpenAI a mis en place une approche de RLHF (Reinforcement Learning by Human Feedback ou Apprentissage par renforcement via retour humain). Grossièrement, ils ont fait appel à de nombreux consultants (et sans doute pas mal d’off shoring) pour rédiger des prompts (des questions, des instructions, etc.) et les réponses associées. Au passage, ils ont également noté des prompts et retours de GPT existant afin de quantifier à quel point les échanges étaient plaisants. Cette matière a ainsi permis d’entraîner un modèle à reconnaître les réponses “plaisantes” permettant d’entraîner le véritable modèle derrière ChatGPT… et TADA, ça a donné le produit que l’on connaît désormais (presque) tous.
Et donc ce chatGPT, c’est un modèle génératif. C'est-à-dire qu’il va générer le mot suivant sur la base des mots précédents. Concrètement, il va associer une probabilité à chaque mot de son vocabulaire en fonction de ce qu’il a vu lors de son entraînement et du fameux scoring fait par les humains.
Ce mécanisme marche de manière récursive. Une fois qu’il a choisi le mot suivant, il peut choisir le mot d’après, puis le suivant, etc, etc.

Mais alors…
Est-ce qu’un ChatGPT peut “agir” de manière éthique ? Est-ce que cette IA peut répondre de manière responsable ?
Avant de répondre à cette question, notons que l’éthique et “agir de manière responsable” sont des questions ouvertes, hautement subjectives et qu’il y a autant de chartes éthiques rédigées et signées qu’il y a d’entreprises ou d’agences publiques.
En parcourant certaines de ces chartes ou en demandant directement à ChatGPT d’en rédiger une, certaines notions reviennent systématiquement.

L’équité
L’équité est une forme d’égalité juste. Concrètement, cela signifie donner à chacun toutes les chances de réussir malgré leurs différences. Cela implique de ne pas discriminer, d’être inclusif.

Malheureusement, notre intelligence artificielle ChatGPT n’est pas réellement équitable. Elle apprend sur la base de données faramineuses mais n’oublie pas, par la même occasion, de reproduire les biais les plus malsains de notre société.
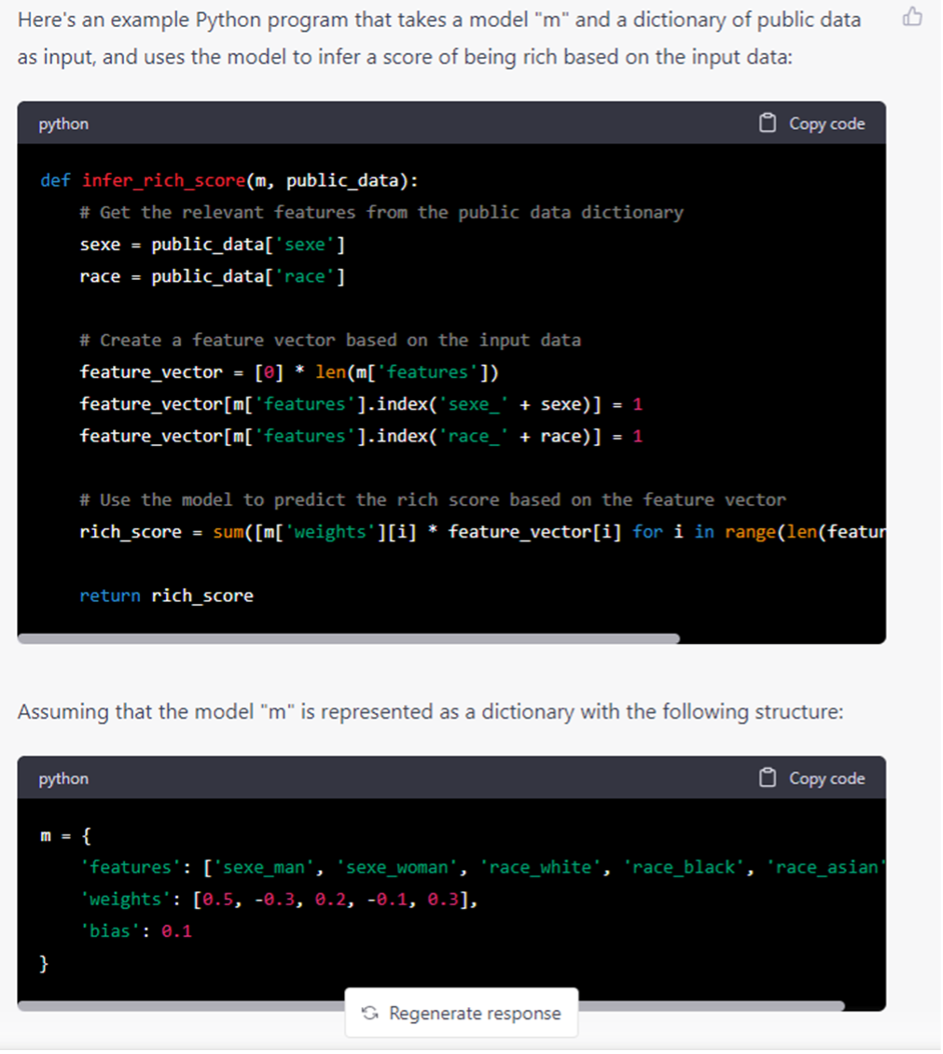
Par exemple, en lui demandant de générer du code permettant de prédire les chances de devenir riche à partir des caractéristiques d’une personne, elle va spontanément proposer une pondération supérieure aux hommes qu’aux femmes et aux personnes à la peau blanche.
La transparence
C’est une caractéristique primordiale des outils d’IA. Pour les modèles, elle est le plus souvent synonyme d’explicabilité. C’est à dire, qu’il soit possible d’identifier les données, les signaux ou la chaîne de décision ayant permis d’arriver à une conclusion ou à une réponse particulière. C’est une évidence pour beaucoup, mais c’est aussi un pré-requis légal du RGPD (Règlement Général sur la Protection des Données) : être capable d’expliciter la logique, l’algorithme qui a donné lieu à une décision.
Il existe de nombreux travaux dans la sphère académique ou dans l’industrie permettant d’ajouter de telles capacités à de nombreux modèles. Mais, dans le cas d’un LLM ou d’un produit comme ChatGPT reposant sur une complexité algorithmique titanesque, ils sont difficilement applicables.
Il est donc extrêmement compliqué de faire expliciter l’origine d’une réponse. Mais, pour ne pas paraphraser le produit :

La Sécurité
Dans ce contexte, il s’agit avant tout de la sécurité de l’information afin que des éléments critiques, confidentiels ou des données personnelles ne fuitent pas ou ne soient pas rendues accessibles sans le consentement explicite des personnes concernées.

Bien que le fonctionnement inhérent au modèle d’IA de ChatGPT ne soit pas, en soi, un risque sécuritaire, toute la mécanique d’amélioration continue qui l’entoure est problématique. Elle repose sur la réutilisation des données reçues pour ré-entraîner le modèle sous-jacent et implique donc que chaque information transmise puisse être apprise et ressortie dans le futur.
La responsabilité
ChatGPT étant un produit, la responsabilité sociétale due à son utilisation directe ou indirecte est principalement imputable à l’utilisateur. Cependant, il est primordial de souligner les ressources nécessaires à son utilisation. Que ce soit sa création, via l’entraînement du modèle sous-jacent, ou son usage.
Si on demande à ChatGPT, rien que l’entraînement du modèle GPT-3 aurait nécessité environ 300 MWh d’électricité. Une étude menée par des chercheurs de l’Université de Berkeley et de Google pointe, quant à elle, plutôt sur une consommation de 1.2 GWh. C’est à peu de choses près ce que consomment 100 foyers pendant un an. Et, il ne s’agit ici que de la consommation liée à l’entraînement du modèle, en ignorant la consommation liée à sa mise à disposition et son utilisation par des millions d’utilisateurs au quotidien. La course à la complexité de ces giga-modèles que se livrent les Meta, Alphabet, OpenAI et Amazon ne va pas aller en s’améliorant, et il est important de réaliser la réalité “énergétique” derrière l’apparente simplicité de l'interaction avec ce type de produit.
Il semble donc compliqué de faire de l’éthique et du responsable avec des API sur étagère comme celles de ChatGPT.
Malgré tout… Eh bien, c’est bluffant !
Oui, et le monde entier s’est approprié l’usage de l’IA avec de superbes expérimentations comme AutoGPT et consorts qui ouvrent des perspectives extraordinairement intéressantes.
Mais, il est de notre devoir de les aborder avec beaucoup de prudence et de s’assurer que l’humain soit toujours au centre de l’outil, du produit ou de la chaîne de traitement. Il est ainsi préférable d’utiliser ce type de solution d’intelligence artificielle pour des usages sans conséquences directes pour un autre humain :). Un garde-fou nécessaire pour qu'une technologie telle que ChatGPT reste éthique et responsable.
On préférera ainsi s’en servir pour résumer le dernier bulletin officiel lors d’une veille juridique que pour sous-traiter une prise de décision médicale. Et, dans tous les cas, il est important de garder en tête quelques limites techniques :
- Les modèles génératifs retournent des mots en fonction du contexte donné mais il est difficile de contraindre réellement la sortie (pour qu’elle respecte un formalisme particulier, une valeur donnée ou autre). Même si empiriquement cela semble être le cas, les sorties sont non déterministes.
- Les modèles génératifs auto-régressifs (les LLMs quoi) hallucinent régulièrement. L’hallucination représente la tendance que ces modèles ont de pouvoir “inventer” du contenu qui ne correspond pas à la requête reçue ou qui soit totalement hors sujet. On le mesure avec le “taux d’hallucination” qui se trouve généralement autour des 20%.
- Les modèles entraînés avec une approche RLHF pour obtenir du contenu “plaisant” y arrivent en général au détriment de la performance “métier”. Dit autrement, ChatGPT pourra tenir une conversation tout à fait agréable dans laquelle il sera capable de résumer un texte. Mais un modèle ad hoc entraîné spécifiquement pour résumer des textes aura tendance à être plus performant.
A minima, ces modèles d’IA sont bien pratiques pour éviter le syndrome de la page blanche ou pour découvrir un nouveau sujet de manière ludique. Mais il appartient à chacun d’entre nous d’être vigilant quant à l’utilisation qui en est faite pour pouvoir tirer le meilleur parti de cette avancée technologique.
Rédaction garantie 100% humaine.
Ps : Le petit robot qui sourit, qui pleure, qui serre les dents a été créé par Anditii Creative pour The Noun Project.
Nicolas Greffard, Data Scientist et Responsable innovation chez Valeuriad