
Le virage Cloud est en train d’être pris à-bras-le-corps par les entreprises françaises. L’attrait des ressources à la demande (à l’heure, à la minute) est réel mais le prix à payer est organisationnel et technique.
Les Ops ainsi que les Devs doivent réapprendre de nouvelles manières de déployer et changer leurs préoccupations en termes d’infrastructure.
Ces préoccupations concernant les services AWS que l’on doit maîtriser sont :
- Le niveau de service (SLA).
- Le degré de consommation de ce service.
- La sûreté de fonctionnement du code applicatif déployé.
Et c’est là que le chaos engineering peut aider à monter en maîtrise sur ces préoccupations : en testant le niveau de service et en vérifiant l’impact applicatif et le bon fonctionnement des procédures de secours automatisées.
En tant que consultant Valeuriad, j’ai été amené à travailler sur le déploiement d’un nouveau produit sur Amazon Web Services (AWS) chez Voyages-Sncf Technologies. Dans une démarche DevOps, nous nous sommes penchés sur une stratégie de test de résilience sur ce produit. Ceci nous a conduit à mettre en place un exercice de chaos engineering inédit nommé “Month of Chaos” qui n’est autre qu’un GameDay étendu.
Pourquoi faire du chaos engineering sous forme de GameDay?
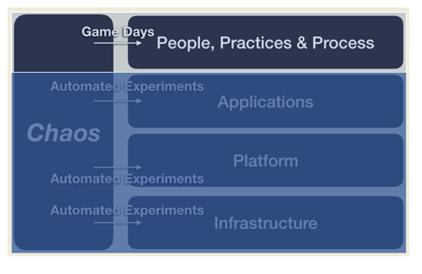
- Rassurer et entraîner votre équipe support, vos exploitants ;
- Tester les processus de bout en bout de gestion d’incident de prod ;
- Tester vos processus d’heures non ouvrées (en spécifiant aux équipes en heures ouvrées de réagir comme en HNO) ;
- Pratiquer les outils plus techniques pour l’analyse (CloudWatch par exemple) de l’incident et son suivi ;
- Chercher des axes d’améliorations de son processus d’incident de production. Il est toujours plus facile dans un climat d’incident provoqué de prendre le temps d’y réfléchir.
Exemple de terrain de jeu

L’architecture repose sur trois AZ (Avaibility Zone), une VPC, deux couches réseau public/privé, bref une architecture classique AWS.
En termes de services, nous avons en vrac : S3, DynamoDB, ElastiCache, IAM, SNS, ECS, EC2, Lambda, RDS, Route53, SES.
La mise en oeuvre du “Month of Chaos” grâce à la Gamification
La recette qui a bien fonctionné pour nous dans cet exercice de chaos engineering sous forme de GameDay :
- Des slides qui présentent les principes, les joueurs, les règles du jeu, le terrain de jeu (le périmètre) ;
- Une réunion en amont pour trouver des pannes ;
- Répertorier les pannes dans une page wiki cachée, uniquement accessible au game master ;
- Une page google formulaire à remplir par le joueur à la fin de chaque panne afin de récolter son feedback et mesurer son niveau de confiance.
Les principes, c’est ce dont nous avons parlé plus haut, à détailler pour votre entreprise et vos processus.
Les joueurs sont les personnes qui sont d’astreintes en général, mais c’est ouvert à n’importe qui. Une personne ne se sentant pas à l’aise techniquement dans l’architecture de votre projet est un très bon candidat à ce jeu !
Les règles de jeu que nous avions défini :
- Le jeu dure 1 mois ;
- Une panne peut survenir de 9h30 à 17h ;
- Les zones impactées peuvent dépasser le compte Amazon de production (usine logicielle externe, réseau, proxy) ;
- Le calendrier d’astreinte doit être prêt et défini pour tous les joueurs ;
- Une panne n’est considérée détectée que si les personnes en début de chaîne l’ont bien détectée et transmise au reste de la chaîne ;
- Si une personne du support de niveau 1 est en difficulté, elle peut appeler un autre joueur (notion de back-up).
Se mettre en condition de HNO : Utiliser le matériel fourni pour l’astreinte (téléphone 4g en partage + ordinateur portable) et interdiction de contacter une autre personne que le back-up.

Trouver les pannes, voila la phase un peu tricky de la recette ! Une panne trop facile à trouver laissera indifférent le joueur tandis qu’une panne trop complexe laissera un goût amer.
Par contre, un joueur qui a déjà joué et qui ne jouera plus peut aider à trouver des pannes avec le Game Master.
Les pannes qui ont bien fonctionné
- Stop d’une ou plusieurs instance(s) EC2 via la console
- Stop de toutes les instances EC2 d’une AZ
- Stop d’un service ECS en mettant le nombre de tâches à tourner à 0
- Delete d’un cluster ECS (/!\ si vous avez de quoi le remonter rapidement)
- Mettre une connexion lente sur votre proxy (assez facile via squid)
- Couper un flux sortant par le proxy (/etc/hosts du proxy, mettre une adresse erronée pour un host donné, un partenaire par exemple)
- Si vous avez une authentification, mettre un espace dans le nom et déclencher une erreur 403. Restez têtu et déclenchez tout le processus de support en vous trompant systématiquement lors des re-tentatives.
- Suppression d’items DynamoDB
- Couper l’accès à la base RDS via IAM
- Supprimer un fichier sur S3

Quelques chiffres et le retour d’expérience des joueurs
Pour présenter le REX, nous avons utilisé RealtimeBoard. Le schéma d’architecture et la chaîne du processus d’incident de prod ont été reportés pour identifier sous forme de post-it numériques les points améliorés durant le GameDay et ceux à améliorer ensuite.
Un autre axe de réflexion pendant ce REX avec les joueurs fût de placer des faits marquants du GameDay au sein du diagramme suivant :
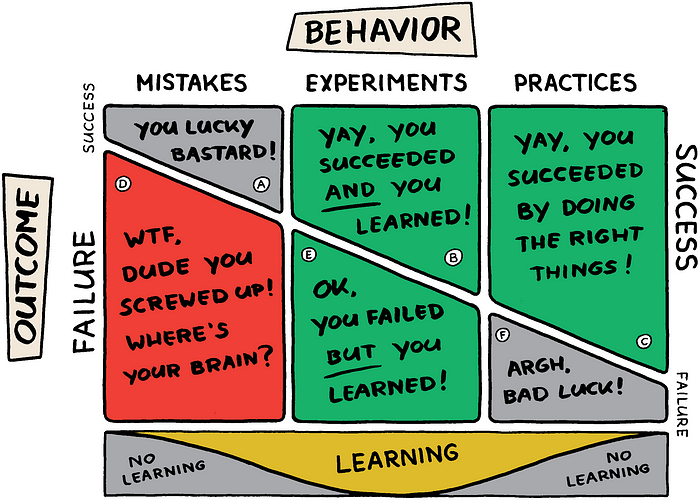
Au total, cela a été une vingtaine de pannes jouées, à peu près 2 par joueur, durant un mois. Toutes les pannes ont été résolues par les joueurs avec, parfois, l’appel à un ami.
Le niveau de confiance par panne a été relevé dans les formulaires google et redemandé de manière plus générale sous forme de nuage de points aux joueurs durant le REX.
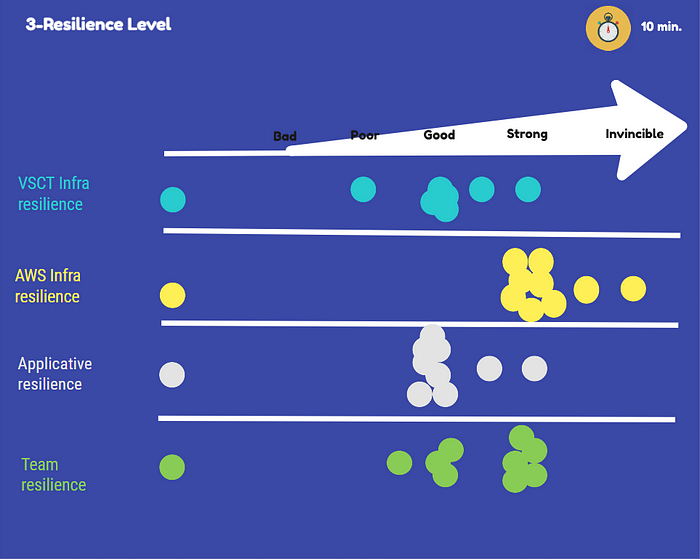
Le niveau de confiance a augmenté. Les joueurs ont bien aimés et en redemande avec — pourquoi pas — des choses plus difficiles.
En dehors du GameDay, quelles sont les autres formes de chaos engineering ?
Si vous voulez faire du chaos engineering mais d’une manière plus libre et/ou plus automatisée, vous pouvez vous référer à mon autre article au sujet de l'automatisation du chaos engineering.
Remerciements
Merci aux Days Of Chaos, implémentés au sein de Voyages-Sncf Technologies et dont nous nous sommes inspirés, qui a été mis en place par Benjamin Gakic.
Des liens qui peuvent vous intéresser :
Documentation AWSConnectez-vous au portail APNTéléchargez du contenu, accédez à des formations et collaborez avec AWS via le site AWS…aws.amazon.comChaos Engineering Meetups | Amazon Web ServicesWe all want to build reliable systems, and some applications are more critical than others. However, how do you know…aws.amazon.comTesting AWS GameDay with the AWS Well-Architected Framework - Review | Amazon Web ServicesAWS GameDay is an immersive, team-based event we have hosted at AWS Summits and re:Invent over the past few years. The…aws.amazon.com
Ecrit par Antoine Choimet, Ingénieur DevOps à Valeuriad et Cyrille Caillaud, Scrummaster Voyages-Sncf Technologies
Articles qui pourraient vous intéresser :
- La théorie du ChaosLe Chaos Engineering est une pratique qui consiste à tester la résilience d'un système informatique en introduisant intentionnellement des défaillances ou des perturbations pour observer comment le système réagit et récupère. L'objectif est de découvrir les faiblesses ou vulnérabilités avant leur apparition dans des conditions réelles. L'idée principale derrière le Chaos Engineering est que les…
- LeHack 2024 - Entre inclusion, intelligence artificielle, cybersécurité et hacking pur et durLeHack est un salon que j'avais particulièrement apprécié en 2023. Contrairement à la Toulouse Hacking Convention et à l'AWS Summit, qui malheureusement se déroulaient tous les deux le même jour cette année, le calendrier me permettait de ne pas manquer LeHack. Si Valeuriad m'a permis de m’y rendre, c'est dans une démarche de veille constante…
- Chaos engineering sur AWS : automatiser ses pannesLa mise en place du chaos engineering se fait en plusieurs étapes. En théorie, la première étape est la mise en place de bonnes pratiques autour du chaos engineering puis une sensibilisation des équipes. Un bon moyen de le faire quand on est sur une infrastructure AWS, ce sont les GameDays (la démarche détaillée ici).…