
La mise en place du chaos engineering se fait en plusieurs étapes. En théorie, la première étape est la mise en place de bonnes pratiques autour du chaos engineering puis une sensibilisation des équipes.
Un bon moyen de le faire quand on est sur une infrastructure AWS, ce sont les GameDays (la démarche détaillée ici).
Une fois cette étape passée, l’équipe ayant compris les enjeux souhaitera aller à l’étape suivante : inclure le chaos engineering dans sa stratégie de test globale.

Sensibiliser l’équipe au chaos engineering via des outils
Pour ce faire, rien de mieux qu’un peu de challenge !
Au sein de Voyages-Sncf Technologies, nous avons développé un outil qui permet de challenger un adversaire via slack. Le but ici est, pour la "cible", de déjouer une panne au hasard, pour l'initiateur, de créer la panne. Ce dernier est appelé “jigsaw" dans notre outil.
Dans la même veine et sans développement, vous pouvez jouer des pannes au hasard grâce à cet outil : https://dastergon.gr/wheel-of-misfortune/
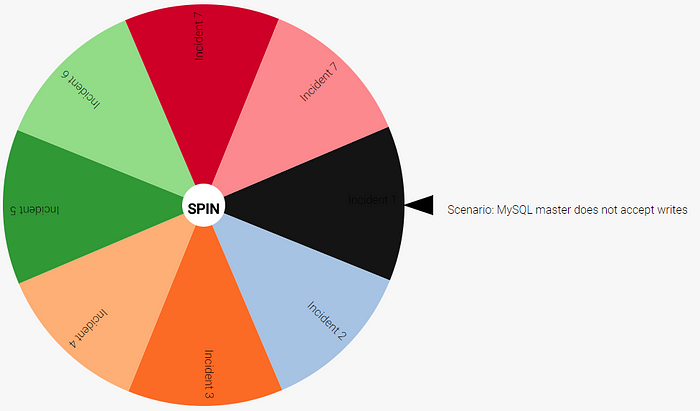
En fin d’article, vous retrouverez des ressources en ligne contenant d’autres outils.
Orchestration du chaos via l’usine logicielle
Où ? Pour le début, il faut un environnement dédié, si possible iso avec la production. Après avoir acquis de l’expérience et de la robustesse dans vos tests/systèmes, il faut se diriger vers la production.
Quelle fréquence ? Pour l’inclure dans votre stratégie de test, libre à vous de choisir entre l’incorporer dans votre pipeline d’intégration continue (mais il faut une certaine confiance car il sera exécuté souvent), ou via un pipeline dédié lancé 1 fois par semaine, par exemple.
Comment ? Notre choix s’est porté sur des pipelines Jenkins. Si vous ne savez pas ce que c’est, vous pouvez lire mes articles dédiés ici et ici. Nous avons un pipeline à la demande pour lancer une batterie de tests de chaos engineering.
Pour automatiser nos pannes, nous avons comparé trois outils dont voici la synthèse en anglais :
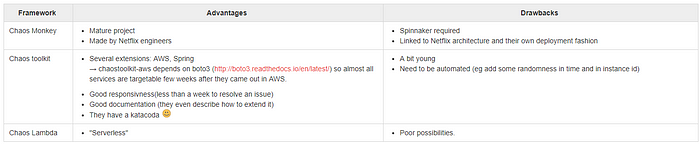
Nous avons été séduits par Chaos ToolKit : open-source, il offre de nombreuses “extensions”. La communauté répond vite, la documentation est claire et ils ont un Katacoda pour se faire la main !
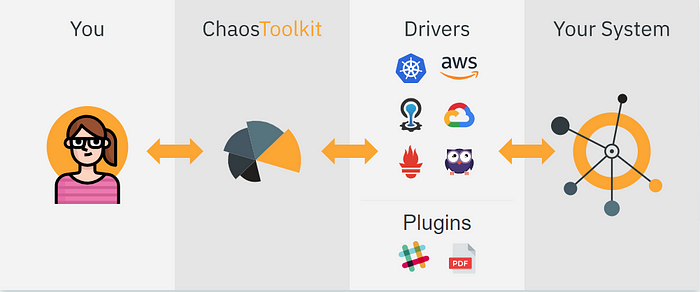
Les pannes propres à AWS que nous avons développé sont directement accessibles dans l’extension AWS du ToolKit :
EC2
- Stop d’une ou plusieurs instances, choisie(s) ou au hasard, pour un service ECS donné
- Stop d’une instance d’une “Avaibility Zone” au hasard ou de toutes les instances de celle-ci
- Stop d’une instance au hasard pour un service ECS donné.service
ECS
- Suppression d’un service donné, au hasard ou au hasard suivant un pattern
Pour voir toutes les autres actions possibles sur AWS, il faut aller sur ce lien.
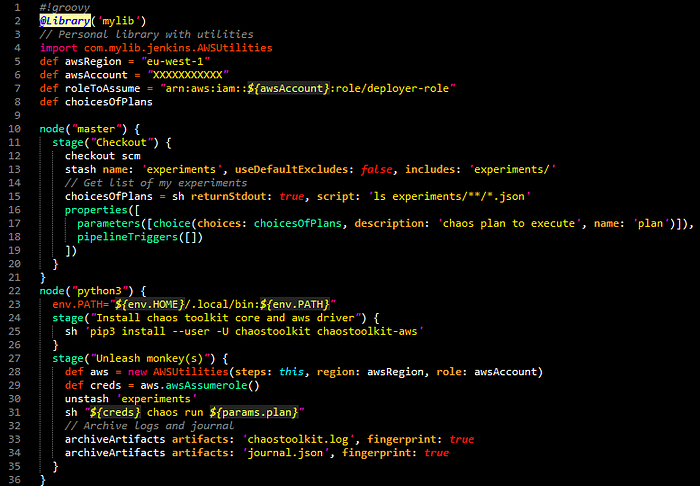
Ensuite, il suffit, via votre pipeline, d’installer - sur une image docker python - le chaos toolkit puis de charger les pannes via un fichier json. Voici un exemple de code :
Comment créer son expérimentation ? Le chaos engineering flow
Tout d’abord, un petit rappel du workflow.
Il faut définir un état stable de votre système. Suite à cela, vous allez tout simplement écrire des expérimentations qui seront appliquées les unes à la suite des autres sur votre système.
Une vérification s’impose à la fin de chaque expérimentation pour savoir si votre système est dans un état caduque ou résilient à votre expérimentation (self-healing, réparation manuelle, circuit-breaker, etc.).
Ce n’est que lorsque le système est détecté défaillant qu’un travail s’engage sur l’analyse de la vulnérabilité.
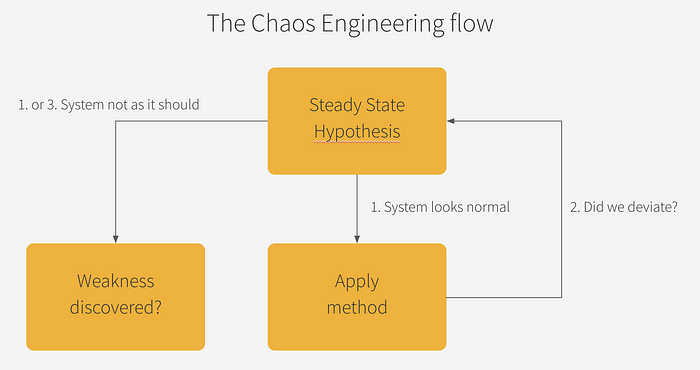
Dans Chaos ToolKit, vous allez retrouver ces notions au sein du fichier d’expérimentation :
{
"version": "0.1.0",
"title": "Moving a file from under our feet is forgivable",
"description": "Our application should re-create a file that was removed",
"steady-state-hypothesis": {
"title": "The file must be around first",
"probes": [
{
"type": "python",
"name": "file-must-exist",
"tolerance": true,
"provider": {
"module": "os.path",
"func": "exists",
"arguments": {
"path": "some/file"
}
}
}
]
},
"method": [
{
"type": "action",
"name": "file-be-gone",
"provider": {
"module": "os.path",
"func": "remove",
"arguments": {
"path": "some/file"
}
},
"pauses": {
"after": 5
}
},
{
"ref": "file-must-exist"
}
]
}
Un peu de détails sur la structure de votre fichier json d’expérimentation, il contient des informations de base :
- version
- title
- description
On rentre dans le vif du sujet avec le “steady-state-hypothesis” :
- title
- probes
Ce sont les “probes” qui vont vous permettre d’exécuter des actions provenant des provider (python, http ou process). Pour AWS, cela passe par la librairie python boto3. Donc, c’est bien le provider python qui est à utiliser.
Ensuite, il y a le bloc “method” permettant de provoquer un chaos, ici la suppression du fichier.
Et, on peut étendre encore la complexité en rajoutant des “rollback”, des “secrets”, voire même une “extension” propre à votre système.
Vous l’aurez compris, c’est assez simple de définir ses expérimentations à condition que vous n’ayez besoin que des méthodes disponibles sur les providers qui vous intéressent. Sinon, il faut passer par la case contribution du projet Chaos ToolKit ou de ses extensions, mais c’est aisé !
Plus de documentation (en anglais) ici sur la définition des expérimentations.
Exploiter les résultats d'expérimentation
Maintenant que vous avez vos expérimentations qui fonctionnent, comment prouver que votre infrastructure ou votre équipe devient plus résiliente au fil des mois ?
Pour cela, vous avez les résultats d’exécutions de Chaos Toolkit, les journaux et les logs un peu plus complètes. Elles sont dans un premier temps suffisantes et retracent bien le workflow cité plus haut. Si votre système n’a pas été résilient, le rollback est déclenché et cela est retranscrit.
Exemple de Journal en sortie d’expérimentation :
https://gist.github.com/achoimet/af1a848d8f3bbfb26084863109b23a1b
Si le ‘json’ vous rebute, une génération en PDF ou HTML est possible grâce à un ChaosToolKit-Reporting.
Si vous souhaitez aller plus loin, vous avez plusieurs choix :
- à l’ancienne, en stockant les résultats de vos expérimentations avec le ressenti, le temps de résolution et la difficulté dans un fichier excel.
- en développant votre propre outil de dashboarding
- partir sur le portail développé par ChaosIQ (l’entreprise derrière la solution OpenSource Chaos Toolkit) : Chaos Hub.

Un mot sur le portail, il permet d’importer ses résultats d’expérimentations, de les visualiser de manière graphique et de les partager au sein de votre organisation.
Il a pour rôle aussi d’agréger vos résultats d’expérimentations sous forme de “Chaos Report”, ce même rapport peut-être exporté.
Le portail n’est pas encore sorti officiellement à l’heure ou j’écris ces lignes, mais en exclusivité, voici quelques aperçus :
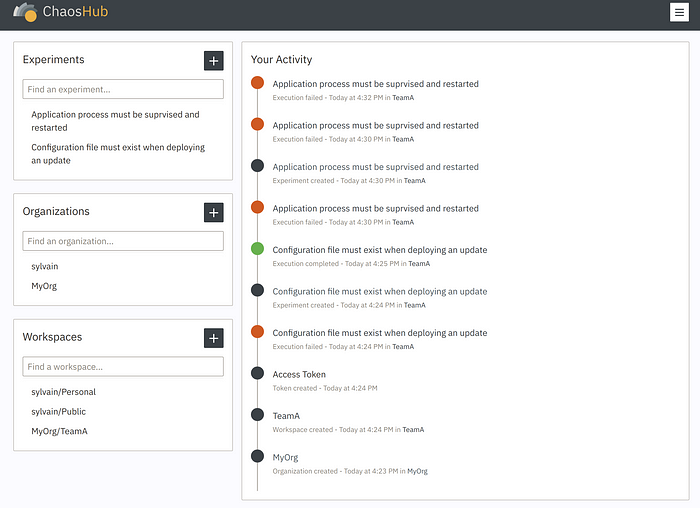
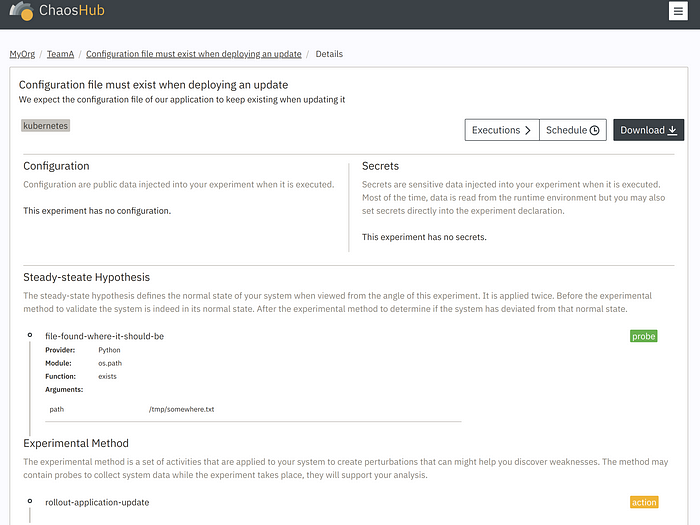
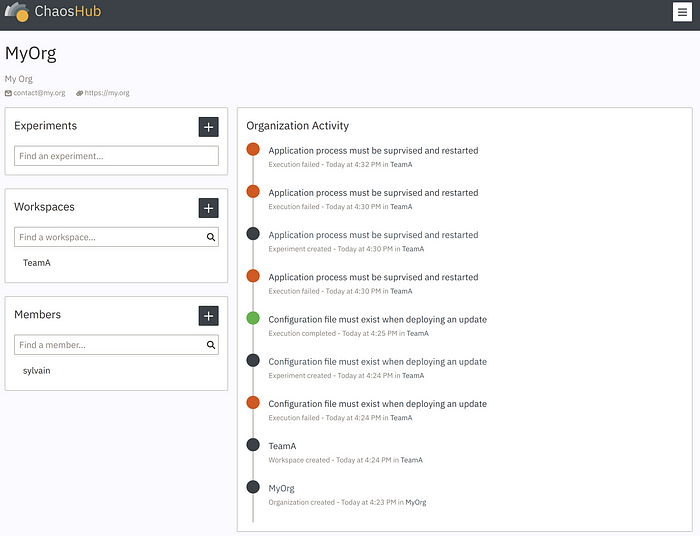
N’hésitez pas à manifester votre intérêt via le site de ChaosIQ !
Conclusion
Comme vous avez pu le voir, en cherchant un peu, il n’est pas impossible d’automatiser le chaos engineering. La communauté est là, les outils fleurissent de plus en plus grâce au chemin ouvert par Netflix.
Je vous invite à parcourir les liens utiles en fin d’article pour trouver encore plus de moyens de mettre en oeuvre une stratégie de Chaos Engineering dans votre contexte.
Remerciements
Je tiens à remercier le cofondateur de ChaosIQ, Sylvain Hellegouarch pour sa venue sur Nantes pour présenter ses solutions et parler du Chaos Engineering et de ses expériences en dev’ !
Un grand merci aussi à Antoine Carat pour avoir pris à bras le corps ce sujet de Chaos Engineering pour son mémoire de fin d’études et avoir fait avancé le sujet dans notre équipe au sein VSC Technologies.
Des liens utiles
dastergon/awesome-chaos-engineeringawesome-chaos-engineering - A curated list of awesome Chaos Engineering resources.github.comThe Netflix Simian ArmyKeeping our cloud safe, secure, and highly availablemedium.comPrinciples of Chaos EngineeringEdit descriptionprinciplesofchaos.orgChaos ToolkitThe Chaos Toolkit is pretty coolchaostoolkit.org
Articles qui pourraient vous intéresser :
- La théorie du ChaosLe Chaos Engineering est une pratique qui consiste à tester la résilience d'un système informatique en introduisant intentionnellement des défaillances ou des perturbations pour observer comment le système réagit et récupère. L'objectif est de découvrir les faiblesses ou vulnérabilités avant leur apparition dans des conditions réelles. L'idée principale derrière le Chaos Engineering est que les…
- LeHack 2024 - Entre inclusion, intelligence artificielle, cybersécurité et hacking pur et durLeHack est un salon que j'avais particulièrement apprécié en 2023. Contrairement à la Toulouse Hacking Convention et à l'AWS Summit, qui malheureusement se déroulaient tous les deux le même jour cette année, le calendrier me permettait de ne pas manquer LeHack. Si Valeuriad m'a permis de m’y rendre, c'est dans une démarche de veille constante…
- Chaos engineering sur AWS : automatiser ses pannesLa mise en place du chaos engineering se fait en plusieurs étapes. En théorie, la première étape est la mise en place de bonnes pratiques autour du chaos engineering puis une sensibilisation des équipes. Un bon moyen de le faire quand on est sur une infrastructure AWS, ce sont les GameDays (la démarche détaillée ici).…